目标检测-SSD300
一、 什么是目标检测

输入一张图片,我们能检测到图像中,哪一些是我们想要的物体、人体信息,那一些是背景,并且图像中的目标,标注出来,并且知道图像中是什么。
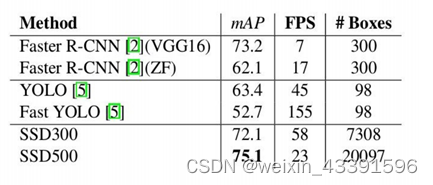
二、 SSD300目标检测的优点

目标检测算法之间的准确率,速度比较:
三、 SSD300的网络结构
SSD的最终预测,没有使用全链接层进行预测,而是用卷积进行预测

SSD网络与传统的目标检测不同,SSD使用不同尺寸的特征图进行预测,如在SSD网络中使用了VGG-16网络,将VGG-16网络中的Conv5-3,后续的Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2的特征图都进行预测。
SSD的VGG-16网络结构:

SSD在VGG-16的Conv4_3后,做了一层L2Normalization,在输出进行预测
L2Normalization:

因为Con4_3层还属于比较靠前的卷积层,他里面的特征值,有的比较大,有的比较小,如果直接将Conv4_3直接进行输入,会发现大的特征值对我们后续的输出影响很大,特征值小的对输出影响十分小,我们不希望出现这种现象,我们希望所有的值都对输出有影响,所以加入了L2Normalization
四、 SSD的Anchor

当输入的图像如上图所示是一个8x8的尺寸,图像中具体有些是目标,哪一些不是目标,这都是未知的,需要通过Anchor来检测是否存在目标,所以每一个像素都有不同尺寸、不同宽高比的Anchor,通过检测所有像素的Anchor,来预测那些Anchor中包含了目标,那些并没有包含目标。
(1) Anchor的尺寸

随着特征图尺寸的减小,Anchor所对应的数量、尺寸也越来越小,因为随着特征图尺寸的减小,感受野会增大, 一个像素所对应原图的信息则越多。
当想要检测的目标较小时,应该在尺寸较大的特征图进行检测,当想要检测的目标较大时,应该在尺寸较小的特征图进行检测。
Anchor的数量与特征图的大小有关,因为特征图越小,对应的像素数量越少,Anchor数量也越少,但感受野大,对应Anchor的尺寸会变大。
(2) Anchor的宽高比

Anchor根据不同的宽高比,能生成不同类型的Anchor,有的宽高比是1:1 或者1:2等,这些都可以根据要检测目标大小进行修改
(3) Anchor的中心位置

(4) SSD300网络的Anker的数量

如上图所示,将VGG-16网络中的Conv5-3,后续的Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2的特征图进行输入,能获取到的Anchor总数量为8732个,不同特征图获取的Anchor数量不同。计算如下:
设定好每个像素值产生四个Anker,Conv5-3的特征尺寸为3838,那么总的Anchor数量为3838*4=5776个,后续的以此类推,最终Anchor的总数量为8732个
五、 SSD预测
SSD是全卷积神经网络,使用来卷积进行预测,而不是像普通的神经网络,最终会由全连接层来进行预测。
(1) Anchor的筛选:
通过SSD网络后,我们得到8732个Anchor,不会将全部的Anchor都去做预测和计算损失函数。将所有的Anchor与真实标签的boxes进iou计算,当计算出来的iou
大于我们的阈值后,才会进行预测和计算损失函数
Iou:

IOU就是把预测框与真实框的交集比上预测框与真实框的并集
(2) 一个Anchor要预测的次数:


当要对某一个Anchor进行预测时,需要做 (4+类别总数) 次预测,获取到对应的值。类别总数是指该Anchor的内容属于哪个类别的可能性大小,获得属于类别总数个概率值。4是指当前Anchor中对应的物体的x,y,w,h的值。
(3) 使用卷积做预测:

1、 使用卷积层和全连接层与卷积层和卷积层进行预测分类:

如图所示:
我们图像做完卷积后,进行特征的拉伸,会把图像中的位置信息给丢失,所以全连接层只能对整体图像进行预测分类。而用卷积层进行预测,则不会丢失对应的位置信息,所以能通过不同的位置,预测出不同的类别。而我们的目标检测正好需要这样的预测
2、 用卷积层和全连接层与卷积层和卷积层预测物体中心位置和高宽
使用卷积层+全连接层预测物体中心位置和高宽

使用卷积层+全连接层预测物体中心位置和高宽

六、 SSD的损失函数

(1) 定位损失函数

上图的Dm计算,是在上面的公式中,将真实框的信息转化成预测框的信息,再通过公式计算得出的。
我们希望预测框与真实框相差越小越好,这样说明我们的预测框越接近我们的真实框,但这里的损失函数并不是直接让预测框与真实框相减,而是通过输入的Anchor作为中间计算,因为输入的Anchor我们是知道的,所以通过预测框与Anchor做计算,真实框与Anchor也做计算,得两个值,当这两个值相差越小时,证明这两个框越接近,当相差大时,则这两个框越不接近,
Smooth L1 Loss:

(2) 分类损失函数

七、 Hard Negative Mining(生成负样本)

也对所有Anchor与真实框进行iou计算,进行排序,选取iou高的前几个当做负样本。
八、 Non-max suppression
