mercurial和svn
介绍 (Introduction)
In my previous article, we went over the basics of Mercurial, as well as some arguments why using it is critical for database administrators. Among many reasons, it allows us to easily track history and changes to our scripts, which in turn makes it easier for us to experiment and enhance our toolkit, since we can do so safely without fear of permanently causing damage. In this installment, we are going to go into more depth on the specifics of two feature of Mercurial that, once harnessed, can add significant efficiency to our coding workflows.
在上一篇文章中 ,我们讨论了Mercurial的基础知识,以及一些为何使用它对数据库管理员至关重要的争论。 在许多原因中,它使我们能够轻松跟踪历史记录和脚本更改,从而使我们更容易实验和增强工具包,因为我们可以安全地这样做,而不必担心会造成永久性损害。 在本期中,我们将更深入地探讨Mercurial的两项功能的细节,这些功能一旦得到利用,便可以为我们的编码工作流程带来显着的效率。
分枝 (Branching)
First, let’s go over the concept of branching. Mercurial’s official documentation defines the term “branch” as follows: “Branches occur if lines of development diverge. The term ‘branch’ may thus refer to a ‘diverged line of development’. For Mercurial, a ‘line of development’ is a linear sequence of consecutive changesets.” In other words, we spawn off a new line of development from a base (or “parent”) state of the code. This in turn allows us to continue working on the new branch without disturbing the original.
首先,让我们讨论分支的概念。 Mercurial的官方文档对“分支”一词的定义如下:“如果发展方向不同,就会产生分支。 因此,术语“分支机构”可以指“发展的分歧线”。 对于Mercurial来说,“发展线”是连续变更集的线性序列。” 换句话说,我们从代码的基本(或“父”)状态产生了新的开发线。 反过来,这使我们可以继续在新分支上工作,而不会干扰原始分支。
A common use of this is to create a new branch on which development of a new feature can commence, while still leaving the main (or “default” in Mercurial’s own terminology) branch stable and untouched. The Mercurial wiki has a discussion of this approach which you should review; however I think this is best illustrated with an actual example, written down as it happens.
通常的用法是创建一个新分支,可以在该分支上开始开发新功能,同时仍使主分支(或Mercurial自己的术语中的“默认”)保持稳定且不受影响。 Mercurial Wiki 讨论了这种方法,您应该查看该方法。 但是我认为最好用一个实际的例子来说明,并在发生时写下来。
I have a stored procedure written which collects and displays blocking information in an easily consumable format. Currently, the functionality, while stable, is fairly limited. For example, the procedure only handles certain kinds of resource locks, namely those involving database files, objects (tables, procedures, triggers, functions, etc), extents (a 64kb block of data in SQL Server), pages (a smaller, 8kb block of data; an extent is made up of eight pages), and individual rows of data. However, there’s quite a few other resources that sessions can hold locks on. For example, by altering a database user, we will (for the duration of the session transaction) hold locks that prevent anyone else from further modifying the same principal (SQL’s terminology for user).
我编写了一个存储过程,该存储过程以易于使用的格式收集和显示阻止信息。 当前,功能虽然稳定,但相当有限。 例如,该过程仅处理某些类型的资源锁,即涉及数据库文件,对象(表,过程,触发器,函数等),范围(SQL Server中的64kb数据块),页面(较小的8kb)的资源锁。数据块;一个扩展区由八页组成)以及各行数据。 但是,会话还有很多其他资源可以锁定。 例如,通过更改数据库用户,我们将(在会话事务期间)持有锁定,以防止其他任何人进一步修改同一主体(SQL的用户术语)。
USE tempdb;
GO
CREATE USER [testuser] WITHOUT LOGIN;
GO
BEGIN TRAN
ALTER USER [testuser] WITH DEFAULT_SCHEMA = sys;
GO
SELECT * FROM sys.dm_tran_locks dtl WHERE dtl.request_session_id = @@SPID;
After running this command, you will see the following results. Note the highlighted section, which shows the locks held on the database principal (the fancy term for a user in a database).
运行此命令后,您将看到以下结果。 请注意突出显示的部分,该部分显示了数据库主体上持有的锁(数据库中用户的幻想术语)。

I would like to enhance my stored procedure to display this information as well, but I don’t want to do so on the main branch in case I discover issues that need to be corrected in the meantime.
我想增强存储过程以显示此信息,但是我不想在main分支上这样做,以防万一我发现需要同时纠正的问题。
The process to complete this operation can be summarized in the following steps.
以下步骤概述了完成此操作的过程。
- Create the new branch. 创建新分支。
- Complete the work required for the feature, committing along the way as necessary (it’s a good idea to do frequent commits to have relatively stable save point of work). 完成功能所需的工作,并在必要时进行提交(最好进行频繁的提交,以具有相对稳定的保存工作点)。
- Merge the branch back to the main ( “default” ) branch when development is complete. 开发完成后,将分支合并回到主分支(“默认”)。
Let’s go through each of these.
让我们逐一讲解这些。
Creating a branch in Mercurial is as simple as issuing a command.
在Mercurial中创建分支就像发出命令一样简单。
PS C:\A_Workspace\sql-tools> hg branch block_db_principal
marked working directory as branch block_db_principal
(branches are permanent and global, did you want a bookmark?)
PS C:\ A_Workspace \ sql-tools> hg分支block_db_principal
将工作目录标记为分支block_db_principal
(分支机构是永久性的并且是全球分支机构,您想要书签吗?)
Congratulations, you have successfully created a new branch in your Mercurial repository! We can now safely proceed with messing around with things.
恭喜,您已经成功在Mercurial存储库中创建了一个新分支! 现在,我们可以放心地处理事情了。
Note: there are those that would advocate simply cloning a completely separate copy of the existing Mercurial repository for this sort of thing, rather than creating a branch. My personal opinion is that is a little heavy handed, but might be useful in cases where you’re really tearing things up. For a really good discussion of the pros and cons of this approach (and several others), see this blog post. It’s a little out of date, but still very well written and useful.
注意:有些建议只为这种事情而克隆现有Mercurial存储库的完全独立的副本,而不是创建分支。 我个人认为这有点费力,但在您确实要撕毁的情况下可能很有用。 要对这种方法(以及其他几种方法)的利弊进行很好的讨论,请参阅此博客文章 。 它有点过时了,但是仍然写得很好并且有用。
Once the branch has been created, you can proceed to make your changes as you normally would. When they are complete and ready to be committed, simply use the “hg commit” command that we talked about in the previous article. There’s no need for any additional options to ensure that the change is committed to the specific branch we created, as Mercurial automatically switched to the new branch when it was created. We can verify this by running the “hg log”command.
创建分支后,您可以照常进行更改。 完成并准备好提交后,只需使用上一篇文章中讨论的“ hg commit”命令即可。 由于Mercurial在创建新分支时会自动切换到新分支,因此无需其他任何选项即可确保更改已提交到我们创建的特定分支。 我们可以通过运行“ hg log”命令来验证这一点。
PS C:\A_Workspace\sql-tools> hg log -l 1
changeset: 88:e13dd43f3a7e
branch: block_db_principal
tag: tip
user: yardbirdsax
date: Sun Jan 31 17:52:09 2016 -0500
summary: Finished enhancement to also show locks / blocks on database principals.
PS C:\ A_Workspace \ sql-tools> hg日志-l 1
变更集:88:e13dd43f3a7e
分支:block_db_principal
标签:小费
用户:yardbirdsax
日期:2016年1月31日星期日17:52:09 -0500
摘要:已完成增强,还可以显示数据库主体上的锁/块。
We can also see this in the graphical interface by right clicking in the folder where the file resides and selecting “Hg Workbench”.
我们还可以通过在图形界面中右键单击该文件所在的文件夹并选择“ Hg Workbench”来查看此信息。

At this point we could continue to experiment on the modified code, or if we are at a good stopping point, we can proceed to merge the changes back into the main (or “default”) branch.
在这一点上,我们可以继续尝试修改后的代码,或者如果我们处于一个良好的停止点,则可以继续将更改合并回主分支(或“默认”)。
Merging in this context simply means that the changes made on the experimental branch will be applied to the relevant files in the main branch. In this case, this was a relatively simple change that only resulted in one revision, however it’s important to note that if multiple revisions were committed on the experimental branch they would all be merged in upon running the merge command. This is important to understand, since there may be times when we don’t want to incorporate all changes made on another branch; perhaps we’ve incorporated a number of experimental tweaks, but only want to merge in a few of them. In that case, rather than a merge, we would use the “graft” functionality, which allows for individual revisions to be moved into another branch.
在这种情况下进行合并仅意味着在实验分支上所做的更改将应用于主分支中的相关文件。 在这种情况下,这是一个相对简单的更改,仅产生一个修订,但是必须注意,如果在实验分支上提交了多个修订,则它们将在运行merge命令时全部合并。 了解这一点很重要,因为有时我们不想合并在另一个分支上所做的所有更改; 也许我们已经合并了许多实验性的调整,但只想合并其中的一些。 在这种情况下,我们将使用“移植”功能 (而不是合并),该功能允许将各个修订版本移至另一个分支。
It’s also important to note that if changes have been made in parallel to the main branch, it’s possible that conflicts will occur. In this case, Mercurial will let you know that this is the case, and present you with a graphical screen to manually resolve the conflicts. Generally this isn’t necessary, as Mercurial does an excellent job of merging on its own, however I’d recommend becoming familiar with how to do this so that when it happens, it doesn’t throw you off your game. For an excellent tutorial and explanation of this process, see this link.
还需要注意的是,如果与主分支并行进行更改,则可能会发生冲突。 在这种情况下,Mercurial会告诉您这种情况,并为您提供图形屏幕以手动解决冲突。 通常,这不是必需的,因为Mercurial可以很好地完成自身的合并,但是我建议您熟悉如何进行合并,以便在发生这种情况时不会使您离开游戏。 有关此过程的出色教程和说明,请参见此链接 。
In our case, neither of these situations will occur, so we can simply use the standard merge command. First, we need to move back into the main branch, which is accomplished using the “hg update” command. Then, we run the “merge”command, specifying the name of the branch we’d like to merge from. Finally, we commit the changes.
在我们的情况下,这两种情况都不会发生,因此我们可以简单地使用标准的merge命令。 首先,我们需要移回主分支,这是使用“ hg update”命令完成的。 然后,我们运行“ merge”命令,指定要合并的分支的名称。 最后,我们提交更改。
PS C:\A_Workspace\sql-tools> hg update default
5 files updated, 0 files merged, 0 files removed, 0 files unresolved
PS C:\A_Workspace\sql-tools> hg merge block_db_principal
1 file updated, 0 files merged, 0 files removed, 0 files unresolved
(branch merge, don’t forget to commit)
PS C:\A_Workspace\sql-tools> hg status
M sp_get_block_chain.sql
PS C:\A_Workspace\sql-tools> hg commit -m”Merge of database principal changes”
PS C:\ A_Workspace \ sql-tools> hg更新默认
更新了5个文件,合并了0个文件,删除了0个文件,未解决0个文件
PS C:\ A_Workspace \ sql-tools> hg合并block_db_principal
更新了1个文件,合并了0个文件,删除了0个文件,未解决0个文件
(分支合并,别忘了提交)
PS C:\ A_Workspace \ sql-tools>汞状态
M sp_get_block_chain.sql
PS C:\ A_Workspace \ sql-tools> hg commit -m“数据库主体更改的合并”
The changes are now present in the main branch. If there’s additional work to be done, we can continue to add revisions to the other branch (we merely have to ensure we are pointing to it first, using the “hg update” command again), or we can close the branch if you are done with it.
更改现在出现在主分支中。 如果还有其他工作要做,我们可以继续向其他分支添加修订(我们只需要确保再次使用“ hg update”命令就可以指向该分支即可),或者您可以关闭该分支完成它。
子脚本 (Child scripts)
One of the more powerful conveniences afforded by the use of source control is the concept of child files. Here’s the basic idea: let’s say you have a generic script used to do some kind of work, perhaps applying some configurations to a server. This is done in the same way across all the servers in your environment. That is, it’s done the same until some specific requirement comes up for one server that necessitates a change. Let’s say the change is a small one, in that the other 90% of work done in the script stays the same. While you could simply copy the file and make the modification, by doing so outside of Mercurial you’ve effectively broken the link between the two files. This means that any changes / corrections made upstream to the original file will not get propagated down to the copy.
使用源代码控制提供的更强大的便利之一是子文件的概念。 这是基本思想:假设您有一个通用脚本来执行某种工作,也许将某些配置应用于服务器。 跨环境中的所有服务器以相同的方式完成此操作。 就是说,直到对一台需要更改的服务器提出一些特定要求之前,它都是一样的。 假设更改很小,因为脚本中完成的其他90%工作保持不变。 尽管您可以简单地复制文件并进行修改,但是通过在Mercurial之外进行复制,您实际上已经破坏了两个文件之间的链接。 这意味着对原始文件的上游所做的任何更改/更正都不会传播到副本中。
Instead, we can create the copy through Mercurial itself, thus keeping the two files tied together. Let’s expand out the example given above to see how this works.
相反,我们可以通过Mercurial本身创建副本,从而将两个文件保持在一起。 让我们扩展上面给出的示例,看看它是如何工作的。
Let’s say we have a simple script file that sets the cost threshold for parallelism value. For all the servers across your environment, you want this value set to 25. However, something comes up with one of the servers, and you decide that it would be best in this case to set it lower, say, 10.
假设我们有一个简单的脚本文件,用于设置并行度值的成本阈值。 对于环境中的所有服务器,您都希望将此值设置为25。但是,其中一台服务器会出现问题,因此您决定在这种情况下最好将其设置得较低,例如10。
Here’s exactly how to create the linked copy, and how to make alterations that can be merged into the copies with minimal effort.
这正是创建链接副本的方法,以及如何进行更改的方法,这些更改可以轻松地合并到副本中。
First, make a copy of the file, using Mercurial’s built in “hg copy” command.
首先,使用Mercurial内置的“ hg copy”命令制作文件副本。
PS C:\A_Workspace\repo> hg copy .\serverconfig.sql .\serverconfig.db01.sql
PS C:\A_Workspace\repo> hg status
A serverconfig.db01.sql
PS C:\ A_Workspace \ repo> hg复制。\ serverconfig.sql。\ serverconfig.db01.sql
PS C:\ A_Workspace \ repo> hg状态
一个serverconfig.db01.sql
As you can see, the file has already been added, but not committed. We can now make our changes to the file, shown below using the WinDiff tool.
如您所见,该文件已经添加,但是尚未提交。 现在,我们可以使用WinDiff工具对文件进行更改,如下所示。
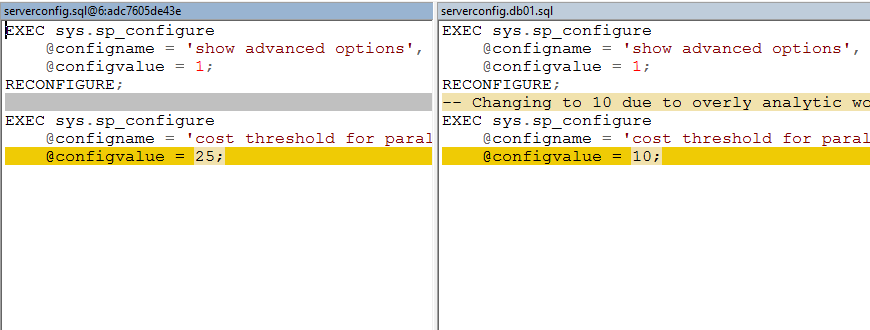
Now we can commit the file.
现在我们可以提交文件了。
PS C:\A_Workspace\repo> hg commit -m”Added copy of Server Config script for db01.”
PS C:\ A_Workspace \ repo> hg commit -m“为db01添加了服务器配置脚本的副本。”
Some time later, we decide that we need to change one of the other setting listed in the file, specifically the one that disables CLR integration. First, we need to determine the revision at which that line was added, using the aforementioned “hg blame” command.
一段时间后,我们决定需要更改文件中列出的其他设置之一,特别是禁用CLR集成的设置。 首先,我们需要使用上述“ hg blame”命令确定添加该行的版本。
PS C:\A_Workspace\repo> hg blame .\serverconfig.sql
6: EXEC sys.sp_configure
6: @configname = ‘show advanced options’,
6: @configvalue = 1;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘cost threshold for parallelism’,
6: @configvalue = 25;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘backup compression default’,
6: @configvalue = 1;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘clr enabled’,
6: @configvalue = 0;
6: RECONFIGURE;
6:
6:
PS C:\ A_Workspace \ repo> hg怪。\ serverconfig.sql
6:EXEC sys.sp_configure
6:@configname =“显示高级选项”,
6:@configvalue = 1;
6:重新配置;
6:EXEC sys.sp_configure
6:@configname ='并行成本阈值',
6:@configvalue = 25;
6:重新配置;
6:EXEC sys.sp_configure
6:@configname =“默认备份压缩”,
6:@configvalue = 1;
6:重新配置;
6:EXEC sys.sp_configure
6:@configname =“启用clr”,
6:@configvalue = 0;
6:重新配置;
6:
6:
Now, we need to change our working folder to point to that revision, using the “hg update” command.
现在,我们需要使用“ hg update”命令将工作文件夹更改为指向该修订版。
PS C:\A_Workspace\repo> hg update 6
0 files updated, 0 files merged, 1 files removed, 0 files unresolved
PS C:\ A_Workspace \ repo> hg更新6
更新了0个文件,合并了0个文件,删除了1个文件,未解决0个文件
Then, we can make our change to the file, which you can see shown below in WinMerge.
然后,我们可以对文件进行更改,您可以在WinMerge中看到如下所示。
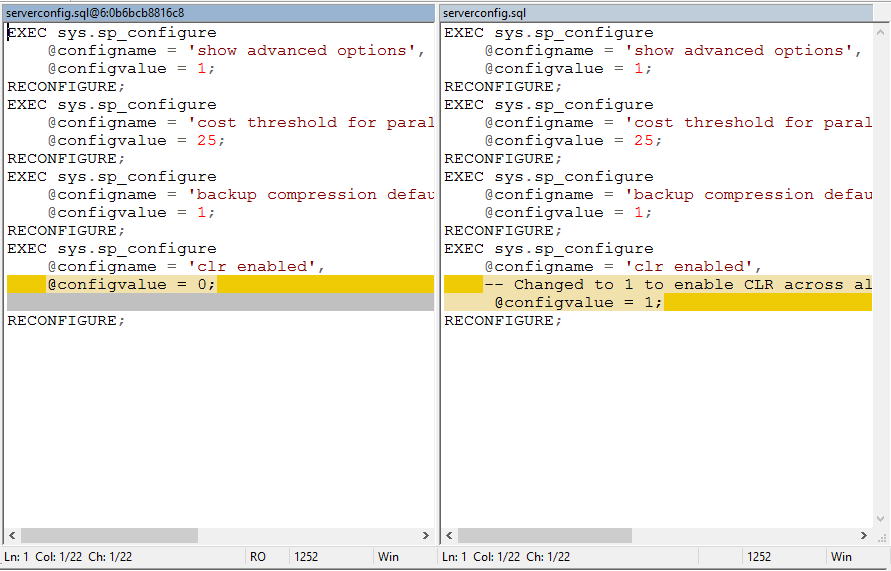
Now, we commit the change.
现在,我们提交更改。
PS C:\A_Workspace\repo> hg commit -m”Updated server config script to enable CLR.”
created new head
PS C:\ A_Workspace \ repo> hg commit -m“已更新服务器配置脚本以启用CLR。”
创造了新的头
As you can tell from that familiar “created new head” message, we now have two lines of code that need to be merged together. Since the changes here are fairly simple, we can run the “hg merge” command and Mercurial will take care of the rest.
从熟悉的“创建新头”消息中可以看出,我们现在需要将两行代码合并在一起。 由于此处的更改非常简单,因此我们可以运行“ hg merge”命令,Mercurial将负责其余的工作。
PS C:\A_Workspace\repo> hg merge
merging serverconfig.sql and serverconfig.db01.sql to serverconfig.db01.sql
0 files updated, 1 files merged, 0 files removed, 0 files unresolved
(branch merge, don’t forget to commit)
PS C:\ A_Workspace \ repo> hg合并
将serverconfig.sql和serverconfig.db01.sql合并到serverconfig.db01.sql
更新了0个文件,合并了1个文件,删除了0个文件,未解决0个文件
(分支合并,别忘了提交)
After a merge operation, it’s important to review all the changed files before actually committing the merge. After all, perhaps the changes you applied might override a change you made in one of the linked scripts on purpose. For example, let’s say we decide to make the default Cost Threshold for Parallelism value 20, rather than 25. Following the steps above, here is what we would do.
合并操作之后,在实际提交合并之前,请检查所有更改的文件,这一点很重要。 毕竟,也许您应用的更改可能会覆盖您故意在其中一个链接脚本中进行的更改。 例如,假设我们决定将“并行性”的默认“成本阈值”设置为20,而不是25。按照上面的步骤,这就是我们要做的。
PS C:\A_Workspace\repo> hg blame .\serverconfig.sql
6: EXEC sys.sp_configure
6: @configname = ‘show advanced options’,
6: @configvalue = 1;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘cost threshold for parallelism’,
6: @configvalue = 25;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘backup compression default’,
6: @configvalue = 1;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘clr enabled’,
8: — Changed to 1 to enable CLR across all servers.
8: @configvalue = 1;
6: RECONFIGURE;
6:
6:
PS C:\A_Workspace\repo> hg update 6
1 files updated, 0 files merged, 1 files removed, 0 files unresolved
…make our changes…
PS C:\A_Workspace\repo> hg commit -m”Updated default cost threshold value to 20.”
created new head
PS C:\ A_Workspace \ repo> hg怪。\ serverconfig.sql
6:EXEC sys.sp_configure
6:@configname =“显示高级选项”,
6:@configvalue = 1;
6:重新配置;
6:EXEC sys.sp_configure
6:@configname ='并行成本阈值',
6:@configvalue = 25;
6:重新配置;
6:EXEC sys.sp_configure
6:@configname =“默认备份压缩”,
6:@configvalue = 1;
6:重新配置;
6:EXEC sys.sp_configure
6:@configname =“启用clr”,
8:—更改为1以在所有服务器上启用CLR。
8:@configvalue = 1;
6:重新配置;
6:
6:
PS C:\ A_Workspace \ repo> hg更新6
更新了1个文件,合并了0个文件,删除了1个文件,未解决0个文件
…做出改变…
PS C:\ A_Workspace \ repo> hg commit -m“默认费用阈值已更新为20”。
创造了新的头
When we issue the ‘merge’ command, Mercurial is smart enough to realize that we’ve modified a line that we touched in a downstream version of the file, and pops up WinMerge to show you the difference.
发出“ merge”命令时,Mercurial足够聪明,可以意识到我们已经修改了在文件的下游版本中触摸过的一行,并弹出WinMerge来显示差异。
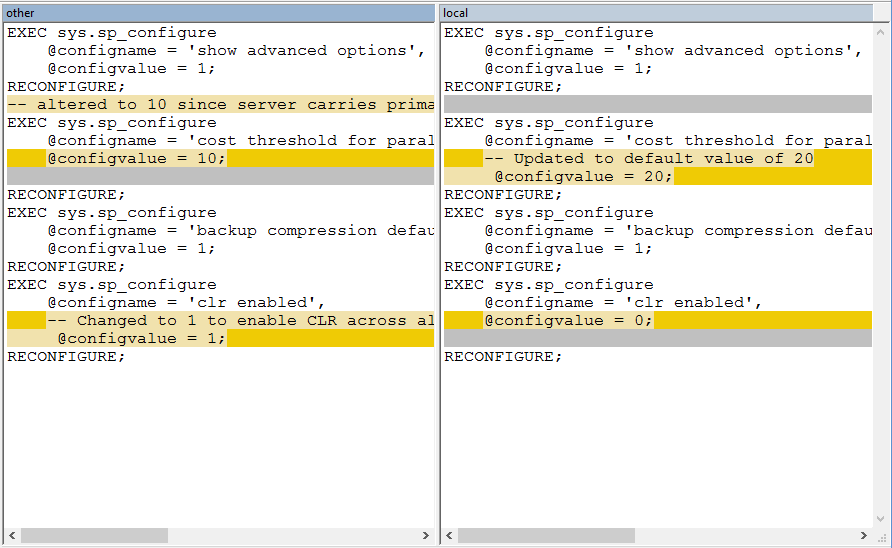
Since we want to keep the line setting Cost Threshold to 10, we right click on that line and select “Copy to Right”.
由于我们要将行的“成本阈值”设置保持为10,因此我们右键单击该行,然后选择“复制到右边”。

Then, click the ‘Save’ button (or just press Control-S).
然后,单击“保存”按钮(或仅按Control-S)。

Note, if we don’t do the same for the second change highlighted above (the change to enable CLR by default), we’ll get an odd result, namely that the change we first made (to set the CLR enable bit) is gone. Why? I don’t want to get into too much detail, but in brief the reason for this behavior has to do with the current revision of our working folder. Since we are currently at a revision based off the earlier one (revision 6), the “merge” command treats that revision as the “gold” one. We could reverse this, however, by first updating to the last revision we worked on before deciding to make this change, which we can see by running the “hg heads” command.
请注意,如果我们对上面突出显示的第二个更改(默认情况下启用CLR的更改)不做相同的操作,则会得到一个奇怪的结果,即我们首先进行的更改(将CLR启用位置1)是不见了 为什么? 我不想太详细,但是总而言之,此行为的原因与工作文件夹的当前版本有关。 由于我们当前的修订版基于较早的修订版(修订版6),因此“合并”命令将该修订版视为“黄金”版。 但是,我们可以通过在决定进行此更改之前先将其更新为我们所做的最后一个修订来扭转这种情况,可以通过运行“ hg heads”命令来查看。
PS C:\A_Workspace\repo> hg heads
changeset: 10:fb84cc84e80a
tag: tip
parent: 6:0b6bcb8816c8
user: yardbirdsax
date: Sun Feb 14 14:51:26 2016 -0500
summary: Updated default cost threshold value to 20.
changeset: 9:093aeb9a93c9
parent: 8:01c3dd64fa0f
parent: 7:5a36eb8916a9
user: yardbirdsax
date: Sun Feb 14 14:50:33 2016 -0500
summary: Merge of CLR enable change.
PS C:\ A_Workspace \ repo> hg头
变更集:10:fb84cc84e80a
标签:小费
父母:6:0b6bcb8816c8
用户:yardbirdsax
日期:2016年2月14日星期日14:51:26 -0500
摘要:将默认成本阈值更新为20。
变更集:9:093aeb9a93c9
家长:8:01c3dd64fa0f
父母:7:5a36eb8916a9
用户:yardbirdsax
日期:2016年2月14日星期日14:50:33 -0500
摘要:CLR合并启用更改。
The key to determining this is noting that the revision we need to target is not tagged as the “tip”, or most forward head.
确定这一点的关键是要注意,我们需要针对的修订版没有被标记为“提示”或最前沿。
Let’s say we already ran the merge command, but luckily we reviewed our changes before committing and noticed. In order to undo the merge and get to a clean state of the proper revision (9), we need to use the “hg update” command with the “-C” switch specified.
假设我们已经运行了merge命令,但是幸运的是,在提交并注意到之前,我们已经检查了更改。 为了撤消合并并达到适当修订版本的干净状态(9),我们需要使用“ hg update”命令和指定的“ -C”开关。
PS C:\A_Workspace\repo> hg update 9 -C
2 files updated, 0 files merged, 0 files removed, 0 files unresolved
PS C:\A_Workspace\repo> hg merge
PS C:\ A_Workspace \ repo> hg更新9 -C
更新了2个文件,合并了0个文件,删除了0个文件,未解决0个文件
PS C:\ A_Workspace \ repo> hg合并
WinMerge will now display, and we can clearly see the changes highlighted, which are the opposite of what we saw earlier. For easy comparison, I’ll present both screenshots below.
现在将显示WinMerge,并且我们可以清楚地看到突出显示的更改,这与我们之前看到的相反。 为了便于比较,我将在下面显示两个屏幕截图。
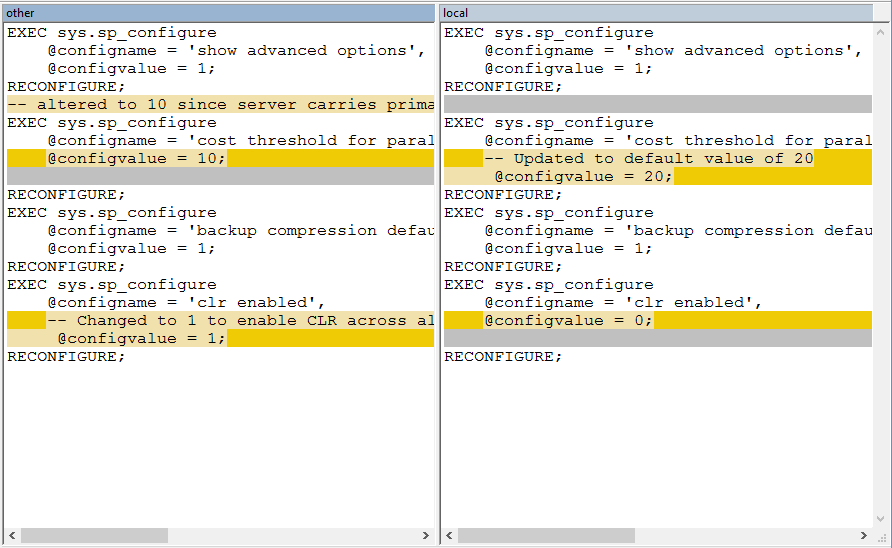
Original
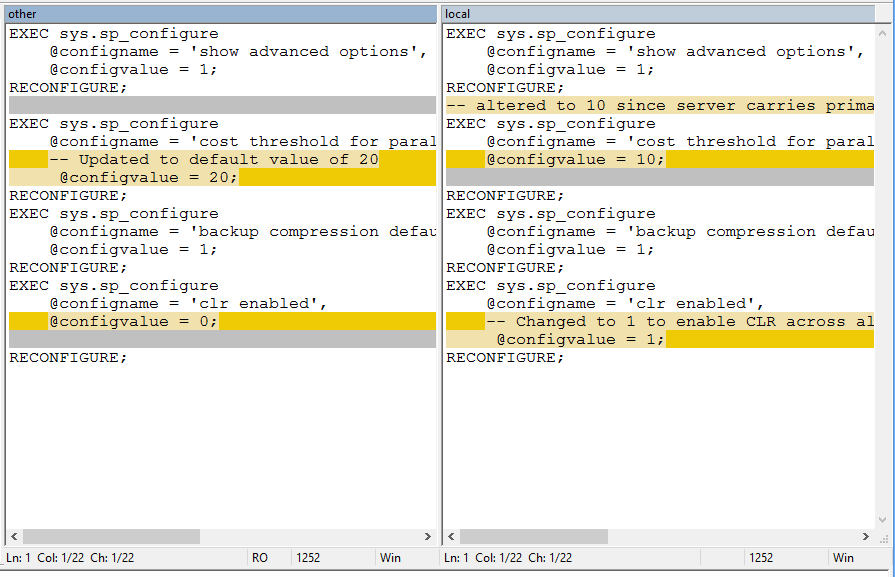
New
In this case, we can clearly see that no changes need to be made (one incoming change overrides something specific to our script, the second overwrites a change we know we later made). All we need to do is close the window, and Mercurial will kindly let us know that no changes have been made.
在这种情况下,我们可以清楚地看到不需要进行任何更改(一个传入的更改将覆盖脚本特有的内容,第二个更改将覆盖我们以后知道的更改)。 我们需要做的就是关闭窗口,Mercurial会通知我们尚未进行任何更改。
merging serverconfig.db01.sql and serverconfig.sql to serverconfig.db01.sql
output file serverconfig.db01.sql appears unchanged
was merge successful (yn)? y
merging serverconfig.sql
0 files updated, 2 files merged, 0 files removed, 0 files unresolved
(branch merge, don’t forget to commit)
将serverconfig.db01.sql和serverconfig.sql合并到serverconfig.db01.sql
输出文件serverconfig.db01.sql保持不变
合并成功了吗(yn)? ÿ
合并serverconfig.sql
更新了0个文件,合并了2个文件,删除了0个文件,未解决0个文件
(分支合并,别忘了提交)
Now, we can commit the changes and move forward!
现在,我们可以提交更改并继续前进!
结论 (Conclusion)
In this article, we’ve introduced two key benefits of using Mercurial to track your scripts and files as a DBA: first, the use of branches as a means to harmlessly experiment or work on enhancements to your code library while keeping a stable version readily available; second, the use of related (or “linked”) copies to make the process of ensuring changes get pushed down into all related files. If this is at all confusing to you, don’t worry. Understanding the nuances of how source control behaves takes time and experience. For example, that whole last section on the differences in behavior of merging two revisions came about after I discovered this very problem writing this article. The end result (a controlled record of changes and ensuring changes are pushed to related files) is surely worth it however. Above all else, don’t be afraid to experiment! Simply make a copy of your existing repository (a simple Copy and Paste of the folder will do fine), and mess around until you get it right.
在本文中,我们介绍了使用Mercurial作为DBA来跟踪脚本和文件的两个主要好处:首先,使用分支作为无害地尝试或对代码库进行增强的方法,同时易于保持稳定的版本可用 其次,使用相关(或“链接”)副本进行确保将更改下推到所有相关文件中的过程。 如果这让您感到困惑,请不要担心。 了解源代码管理行为的细微差别需要时间和经验。 例如,在我发现撰写本文非常困难之后,出现了关于合并两个修订的行为差异的最后一整节。 但是,最终结果(更改的受控记录并确保将更改推送到相关文件)肯定值得。 最重要的是,不要害怕尝试! 只需复制现有存储库的副本(对文件夹进行简单的复制和粘贴就可以了),然后四处乱逛,直到正确为止。
In a future article, I plan on going over some specifics around best practices for various kinds of scripts, such as those for creating SQL Agent jobs, setting up SQL Agent Alerts, and others. For now, I hope you have been convinced that source control (and Mercurial in particular) is a valuable and necessary part of the DBA’s toolbox.
在以后的文章中,我计划讨论各种脚本的最佳实践的一些细节,例如用于创建SQL Agent作业,设置SQL Agent Alerts的脚本等。 现在,我希望您已经确信源代码控制(尤其是Mercurial)是DBA工具箱中宝贵且必要的组成部分。
翻译自: https://www.sqlshack.com/a-dbas-introduction-to-mercurial-branching-and-merging/
mercurial和svn